
 insight
insight 
Vandaag de dag wordt software zelden nog gemaakt door één enkele ontwikkelaar. Eigenlijk zien we vooral meerdere teams samenwerken aan applicaties en oplossingen. Hierbij is feedback van het grootste belang: het laat ontwikkelaars zien, dat de software op een bepaalde manier correct werkt. Het vertelt of de code qua syntax correct is (‘it builds!’), maar ook dat vitale onderdelen nog steeds werken zoals bedoeld is (de ‘unit tests’ slagen!) en dat de wijzigingen van individuele ontwikkelaars elkaar niet in de weg zitten. In dit artikel kijken we naar wat we allemaal aan terugkoppeling kunnen organiseren en op welke manier dat kan bijdragen aan betere software!
“Feedback is bij softwareontwikkeling heel belangrijk, maar het verschil zit hem vooral in het moment waarop het komt.”
De drie feedback loops
We gaan er bij softwareontwikkeling eigenlijk altijd van uit, dat er drie verschillende processen voor terugkoppeling zijn. Deze zogeheten ‘feedback loops’ verschillen niet alleen in detail maar vooral ook in de snelheid waarin ze de informatie aan de ontwikkelaar terugkoppelen. Laten we eerst kijken naar de terugkoppeling, die de meeste ontwikkelaars wel zullen herkennen. Ik noem dit de ‘Inner Feedback Loop’. Deze feedback loop is bijzonder belangrijk, omdat deze terugkoppeling geeft op de code die zojuist door de ontwikkelaar is geschreven. Dit betekent, dat de ontwikkelaar nog niet naar een andere context is geschakeld en de zojuist ingediende code nog vers in het geheugen heeft. In één van mijn favoriete podcasts (.NET Rocks) komt het regelmatig langs: “Feedback should be there before the Developer returns from the coffee machine!”. In de praktijk zou dat dus binnen 15 minuten moeten zijn!
De ‘Inner Feedback Loop’
Dit type terugkoppeling is dus vrijwel direct. Normaal gesproken begint dit al in ontwikkelomgeving lokaal, de IDE (‘Integrated Development Environment’). De meeste van deze IDE’s hebben manieren om ontwikkelaars te informeren hoe het staat met de code terwijl deze wordt geschreven: in de vorm van rode kringellijntjes die aangeven of de code fout of verdacht is. Op de achtergrond is de compiler bezig met het compileren van de code en voert de unit tests uit. Vooral deze testen laten bijna in real-time zien of de code ernstige gebreken bevat. Dit speelt zich nog allemaal af op de lokale machine van de ontwikkelaar, maar zoals we al eerder gezegd hebben: software wordt tegenwoordig nog maar zelden door één ontwikkelaar gemaakt.
Wanneer de ontwikkelaar zijn code af heeft, worden de wijzigingen doorgegeven aan de centrale repository. Op dat moment kunnen een hoop verschillende checks plaatsvinden:
- Compileert de code?
- Slagen de unit- en integratietesten nog?
- Zijn er bevindingen naar aanleiding van een (statische) code analyse?
- Zijn er bevindingen naar aanleiding van een Code Review door een teamlid?
Tegenwoordig gebruiken de meeste teams een 2-staps proces: als eerste dient een ontwikkelaar de wijzigingen in en verpakt deze in een zogeheten ‘Pull Request’. Dit wordt gevalideerd: deels automatisch met behulp van bovengenoemde checks en deels handmatig in de form van een ‘Code Review’. Als de code slaagt voor deze checks, dan wordt ze samengevoegd met de ’main codebase’ of hoofdcode (een samenstelling van alle eerder gemaakte en gevalideerde code). Dit is tevens de start van de tweede terugkoppeling.
De ‘Short Feedback Loop’
In het ideale geval start deze terugkoppeling direct nadat de ingediende code is geïntegreerd met de rest van de code. Normaal gesproken wordt er vanuit deze codebase, direct een versie uitgerold op een omgeving. Maar voordat we uitrollen herhalen we een aantal checks en voeren we een aantal nieuwe checks uit. Het verschil is dat we dit nu doen op de gehele codebase en niet slechts op de ingediende wijzigingen. Dit betekent wel dat deze checks over het algemeen langer lopen en dus meer tijd kosten, maar ook dat we meer/uitgebreidere testen kunnen doen:
- API testen;
- Supply Chain testen waar we onze software nalopen op kwetsbaarheden in afhankelijkheden (zogeheten ‘dependencies’);
- Kunnen we het uitrollen op een testomgeving?
- Geautomatiseerde security scans en performance testen;
- Geautomatiseerde UI testen.
Dit proces loopt een stuk langer vergeleken met de eerste loop, maar verzamelt ook gegevens in meer detail. Toch mag je verwachten dat deze terugkoppeling snel komt. Vooral om ervoor te zorgen dat ontwikkelaars zo min mogelijk verstoord worden, ze zijn immers al aan nieuw/ander werk begonnen. In geautomatiseerde systemen zou je dit soort testen dus het liefst niet in de nacht of wekelijks willen doen, maar direct nadat de wijzigingen aan de hoofdcode zijn toegevoegd. Op die manier kunnen we bevindingen direct terugkoppelen, misschien zelfs via een Slack of Microsoft Teams Channel!
De ‘Long Feedback Loop’
Dit is feedback die we niet direct het team in gooien. Denk aan bevindingen uit ‘Gebruikers Acceptatie Testen’ of foutenmeldingen uit logfiles op productie. In dergelijke gevallen is meestal een vorm van onderzoek of triage nodig en om die reden meer geschikt voor ticket- of bugtracking systemen. En voor feedback waar snel op gehandeld moet worden, denk dan aan ‘emergency hotfixes’, e.d.? Daar kun je het beste een apart proces voor inrichten, want die moeten normaal gesproken zo snel mogelijk door het team opgepakt kunnen worden.
In deze loop vind je dus zaken als:
- De uitrol naar een productieomgeving (succesvol of niet, dat is ook feedback);
- Signalen uit het testen in productie (A/B testing, Blue/Green, Canary Releases, etc.);
- Beschikbaarheidstesten, waarbij downtime meestal zorgt voor zo’n eerdergenoemd ticket waarop snel gehandeld moet worden;
- Gebruikers Acceptatie Testen (User Acceptance Tests) ;
- Handmatige testen door de business of eindgebruikers;
- Toegankelijkheidstesten (Accessibility).
De keten
Als we de drie feedback loops aan elkaar koppelen krijgen we een reeks aan stappen die bestaan uit de checks en validaties. Als we de stappen uit deze reeks willen automatiseren komen we in de meeste gevallen al snel uit bij een zogeheten “Continuous Integration / Continuous Deployment” pipeline.
In de meest eenvoudige vorm geeft CI/CD je controle over de voortbrenging van software door geautomatiseerde stappen. Continuous Integration is het mechanisme waarbij je het werk van individuele ontwikkelaars samenvoegt in de hoofdcode. Je zorgt er dus voor dat de losse wijzigingen goed samenwerken met elkaar én met het werk dat al eerder is gedaan. Continuous Deployment neemt deze wijzigingen zo vaak als nodig uit de hoofdcode en rolt deze direct uit op een (productie) omgeving. Om uit de hele keten de feedback te organiseren (en standaardiseren) kunnen we daarnaast gebruik maken van iets wat ‘Continuous Testing’ heet.
“Testen is feedback. Dus door continu te testen krijg je alle feedback die je nodig hebt.”
Continuous Testing
Laten we kijken naar een voorbeeld waarin het allemaal samenkomt. Het volgende diagram toont een CI/CD pipeline waarin een aantal van de checks en tests zitten die in dit artikel langs zijn gekomen. Hoewel het hier een versimpelde versie betreft van een echte pipeline (te weten van Amped, een Open Source project), zit er toch al aardig wat in. Het zal ook zeker niet op alle situaties van toepassing zijn, maar het toont wel hoe de drie typen feedback samenwerken om waardevolle terugkoppeling te verzamelen.
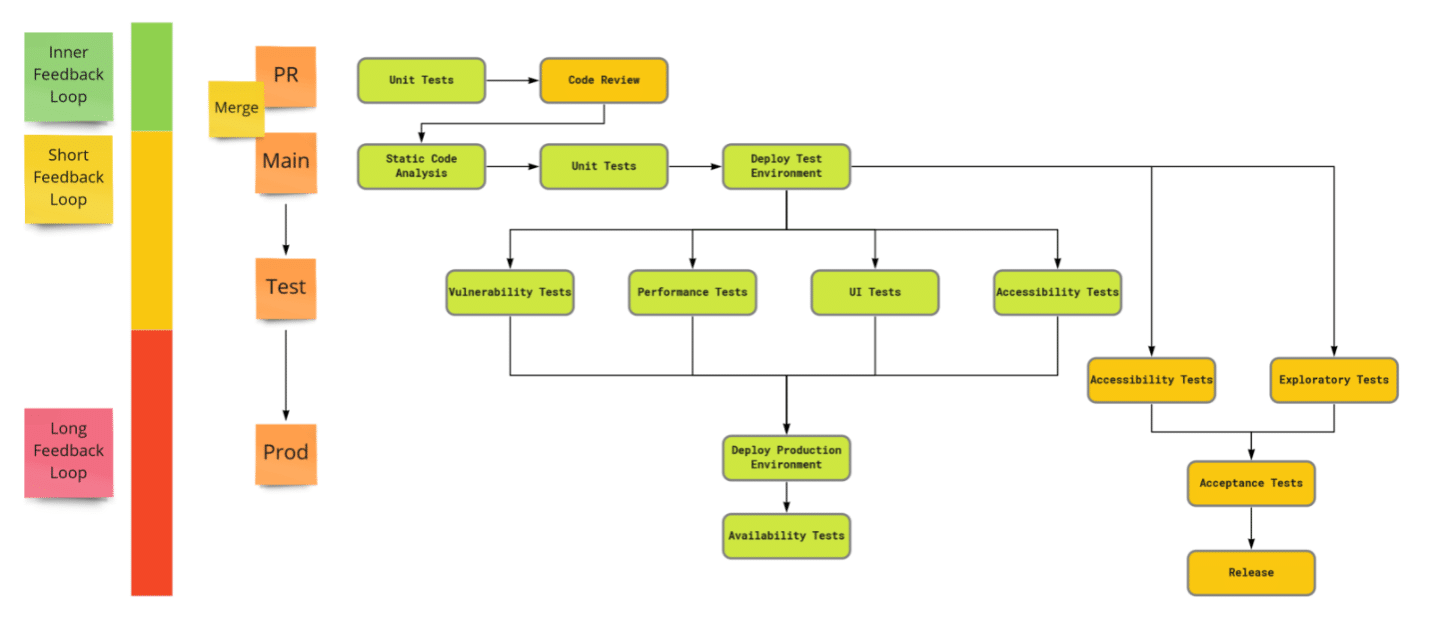
Omdat we, vooral bij de eerste twee feedback loops, zo min mogelijk tijd willen verliezen maken we in dergelijke pipelines in hoge mate gebruik van geautomatiseerde stappen. In dit getoonde diagram zit ook maar één handmatige stap (de ‘Code Review’) op de weg naar de productieomgeving! Deze methodiek kennen we als Continuous Testing, soms ook wel Agile Testing genoemd. Het beschrijft het proces van het uitvoeren van geautomatiseerde testen als onderdeel van de software delivery pipeline om feedback te krijgen op de risico’s van een bepaalde software release. Met andere woorden: wat zijn de (bedrijfs)risico’s van de software die je uitrolt op productie.
De naam is overigens verwarrend, want met Continuous Testing wordt niet bedoelt dat we de hele tijd testen… het betekent vooral dat we in elke fase van het software delivery proces testen hebben zitten die bepaalde risico’s in kaart brengen. Omdat wij toch terugkoppeling willen in elke fase van het proces is dit een mooie methodiek om onze drie feedback loops in onder te brengen!